What is Vector Search? Building a Production-Grade Vector Search System

Introduction to Vector Search
Vector search plays a pivotal role in the evolution of machine learning, serving as essential repositories for numerical encodings of data. Vectors are mathematical entities used to represent categorical data points in a multi-dimensional space. In the context of machine learning, vector databases provide a means to store, retrieve, filter, and manipulate these vectors.
As vector models excel at finding similarities between data points, they are indispensable for large language models, as well as the foundation for many prediction, similarity search, and context retrieval use cases.
By enabling quick and structured access to data representations, vector databases empower machine learning models to process and learn from complex data with remarkable efficiency, facilitating the development of advanced AI applications that continue to reshape industries and technologies.
Qwak Vector Store Overview
Qwak is excited to announce the release of our managed vector store service. The Qwak vector store provides a scalable solution for the transformation and ingestion of vector data, as well as a low-latency query engine that can provide advanced filtering on metadata and properties.
The Qwak vector database fits seamlessly within the Qwak platform, allowing you to easily connect models to the vector database for training and prediction and manage all of your machine learning infrastructure in one place.
Building Production-Grade Vector Search with Qwak
In this tutorial, we will walk through an implementation of the Qwak vector store - building a Qwak model that transforms Wikipedia article texts into embedding, storing that embedding data in the Qwak vector database with relevant metadata related to the articles, and finally, querying the vector database to retrieve objects similar to our search criteria.

Create a Model for Vector Transformation
First, we’ll need to create a model that transforms and embeds our input text so that it can be persisted in the Qwak vector database. Luckily, we can do this all on the Qwak platform.
For this model, we’ll be using the sentence transformer all-MiniLM-L12-v2 model from Hugging Face. We first import the QwakModel class from the qwak-sdk and define our base model.
We’ll need to define two functions, the `build` function and the `predict` function. Because the model is pre-trained, we can simply pass our build function and set ```self.model``` to an instance of the SentenceTransformer.
In the predict function, we’ll define how our model will handle input data.
We transform our input text into a list, so that it can be handled by the SentenceTransformer encode logic, define the batch size, and add a few configuration settings. We return a DataFrame with field output and value of a list of vectors.
We’ll need to build and deploy it as a real time endpoint so we can call our embedding function when querying the vector database. You can find an example of this model at our Qwak examples repository.
1. Clone the repository locally, and make sure you have the Qwak CLI installed and configured.
2 Once in the directory, run make build to kick off the training job for this model. You can navigate to the Models -> Builds tab in the Qwak UI and monitor the progress of the build.
3. Now that the model has been successfully trained and stored in the Qwak Model Repository, you can run make deploy to take this build version and deploy it as a real-time endpoint. You can also monitor the Deployment steps by going to the Models -> Deployments tab in the Qwak UI.
4. When the Deployment completes, click on the Test Model tab in the upper right hand corner of the platform, and Qwak will generate example inference calls that you can use to call your real time endpoint and test your predictions live!
Read more about the Qwak Build and Deploy process here.
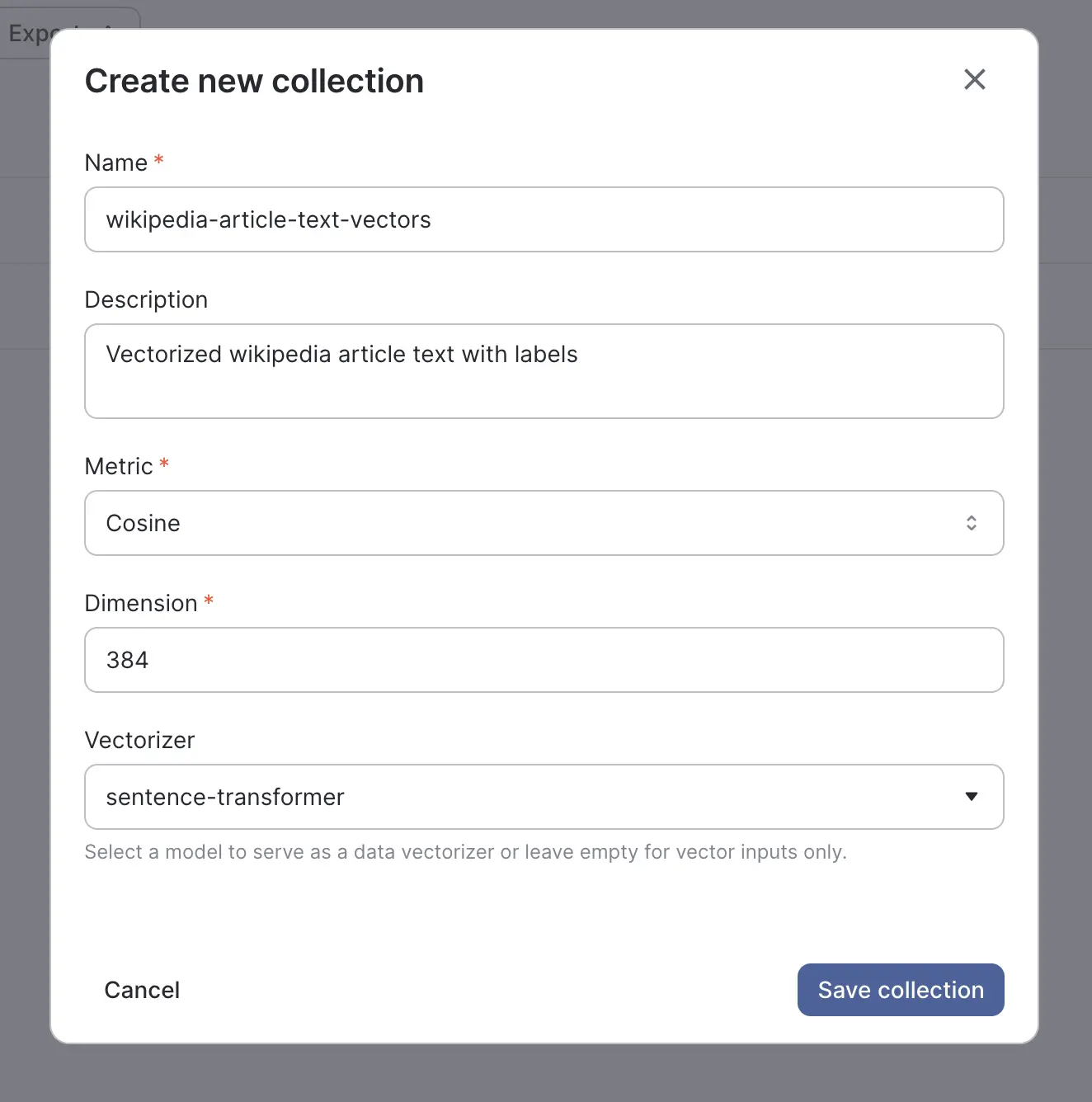
Create Collections
Collections are a Qwak organizational feature that allow you to structure and manage your various vector groupings across your vector database. Collections allow you to specify the metric configuration(cosine, L2) as well as the number of vector dimensions, providing fine grained control over the grouping and indexing of your data.
You can create collections in the UI, or define the collections as code using the qwak-sdk. For this tutorial, you can see an example collection we’ve created below. We select the cosine metric for grouping and 384 dimensions to be used in the vector plane. We also need to select a vectorizer.
A vectorizer is a deployed Qwak model that accepts data as an input and returns a vector in its predict function - just like the model we created in the previous step! Here we select the sentence-transformer model that is running in the Qwak platform, and the Qwak vector database will automatically use this model’s embedding function when preparing input data for insertion or searching the vector database, allowing us to send free text to the Qwak collections API.
Now that we have our model deployed and our collection in place, we are ready to start using our vector database.
Inserting Data into the Vector Database
With our LLM, embedding model, and collection in place, we are ready to insert our documentation into the vector database. We’ve collected the documentation as a series of raw markdown files.
Let’s install our project dependencies first.
We have a source parquet file that contains a series of Wikipedia articles and their contents. We also have fields for url, article title, and text length that we will use as properties for our vectors.
We first read the parquet file into a Dataframe using pandas, and filter out articles that do not contain text.
Next we’ll need a unique identifier for each vector that we store, so we’ll select the article id field. We’ll also select the properties that we want to include with our vectors. Fortunately, these fields are fairly straightforward so we won’t have to do much transformation.
Now we need to get our vectors!
We will take the text field from the input data frame, and send this data to our sentence-transformer model that will execute the prediction function and return our embeddings. Using the “natural_inputs” parameter, the collection upsert command will call the real time model on Qwak for us.
And finally, we will put it all together and send our ids, vectors and properties to the Qwak vector database. With the Qwak VectorStoreClient, we find the collection that we created in the previous step, and we use the `upsert` method to push and index our data into the vector database.
Querying the Vector Database
Now that our vector database has been populated, let’s use it! Let’s query our vector database to see if it has any content related to ducks. We can use the same VectorStoreClient that we created in the upsert step. We take our query, “ducks”, and make a request to our sentence-transformer model to get our query vector. Then we pass that vector into the client’s `search` method. We can specify the number of results and the vector properties that we want returned. We can also return the distance between our input vector and the returned results, if we want to gauge the query performance or quality of our vector indexing.
We specify to the client to return the title, title_len, url of the three closest articles and here are the results!
Our query returned articles related to the Carolina Hurricanes, who were Stanley Cup champions in 2007, right before the Anaheim Ducks, ‘Quack’ the noise that ducks make, and a ‘liver bird’, a water fowl often misidentified as a duck. Not the best search result, but for only a few thousand article vectors, we’ll take it! You can use the metric feature of collections to experiment with different distance calculations and measure how they affect performance.
Summary
The Qwak vector store is available now and you can get started today by going to the Collections tab in the Qwak UI and creating a new collection. To learn more about all the Qwak vector database functionality, you can visit our documentation or reach out to a member of the Qwak team.
Say goodbye to complex AI & ML
Chat with us to see the platform live and discover how we can help simplify your journey deploying AI in production.
