How to Build Your Own Text Classification Workflow Using fastText

When working with machine learning (ML) in production, the model choice is just one of a slew of important criteria. Equally important are the definition of the problem, gathering high-quality data, and the architecture of the machine learning pipeline.
In this article, we are going to look at how you can overcome a very common challenge: building a multiclass text classification workflow. We’re going to use fastText, an open-source, free, lightweight library that allows users to learn text representations and text classifiers.
It was created by Facebook's AI Research lab. The model allows users to create an unsupervised learning or supervised learning algorithm for obtaining vector representations for words across 294 languages.
What’s more, we’re going to do this using fewer than 25 lines of code!
But first, what is text classification?
Unstructured text is everywhere. It’s in our emails, chat conversations, websites, and social profiles. It’s hard to extract any real value from this data unless it’s organized in a particular way through a process known as text classification.
Text classification is a very basic ML technique that’s used to classify text into different categories. It’s ubiquitous in the ML space and there’s no shortage of use cases for it. Spam filtering, product review classification, and sentiment analysis are just some of the main ones.
Carrying out text classification used to be a difficult and expensive process, since it required spending time and resources to manually sort the data. However, times have changed. Nowadays there are many tools available, such as fastText, which do most of the work for us.
Text classification is becoming - important to businesses because it enables them to collect valuable insights from their data and automate processes. Some common examples of text classification include:
- Sentiment analysis — The process of understanding the context of a piece of text, such as if a piece of text is talking positively or negatively about a given subject. This is useful for monitoring customer reviews.
- Topic detection — Identifying the theme or topic of a piece of text, for example knowing if a customer review is about a particular subject such as customer support or a particular product.
- Language detection — This detects the language used in a piece of text so that information can be routed to the right people.
In our example, we will use supervised classification of text. It works on the principles of “training” and “validation”. In essence, we input labeled data to the machine learning algorithm to work on. After the algorithm is trained, we use the training dataset to understand the accuracy of the algorithm and training data.
The overall effectiveness and accuracy of the output depends on the quality of the data it’s trained on and the strength of the algorithm. Because we’re using fastText, we don’t need to create our own algorithm, which eliminates a lot of the heavy lifting.
Classifying customer complaints using fastText
In this example, we’re going to build on the theme of customer feedback by classifying real customer complaints into one or more relevant categories using fastText.
As we mentioned earlier, fastText is an open-source, free, lightweight library that allows users to learn text representations and text classifiers. It works on standard, generic hardware that has been open sourced by Facebook.
Installing fastText
Installing fastText is very easy, but there are some things to be aware of. Because fastText builds on modern Mac OS and Linux distributions. Since it uses C++11 features, it requires a compiler with good C++11 support.
Compilation is carried out using a Makefile, so you will need to have a working make. For the word-similarity evaluation script you will need:
- Python 2.6 or newer
- NumPy & SciPy
You can then either build fastText as a command line tool or as a Python module.
Building fastText as a command line tool
To build fastText, use the following:
Building fastText Python Module
To build fastText module for Python, use the following:
Then verify that the installation was successful:
If you don’t get an error message, then you’re good to go.
Getting and preparing your data
First you need to download the consumer complaints CSV file from here.
This dataset has official, real complaints received about financial products and services in the United States. These complaints are neatly categorised into various products. The CSV file contains many data points, including:
- Date received
- Product
- Sub-product
- Issue
- Sub-issue
- Consumer complaint narrative
In our example, we’re going to be trying to solve a simple problem statement: When a customer writes a new complaint, how do we categorise it into a product automatically?
Read and process your CSV file using the following Python code:
You should be met with an output that displays the product being complained about and the relevant narrative to the complaint. fastText expects this data to look something like this:
__label__1 this is my text
__label__2 this is also my text
We need to prepare product data, and the output should look like this:
__label__product complaint text
We can now build on the previous code:
Check the contents using the command consumercomplaints.head(200)
The output will be something along these lines:
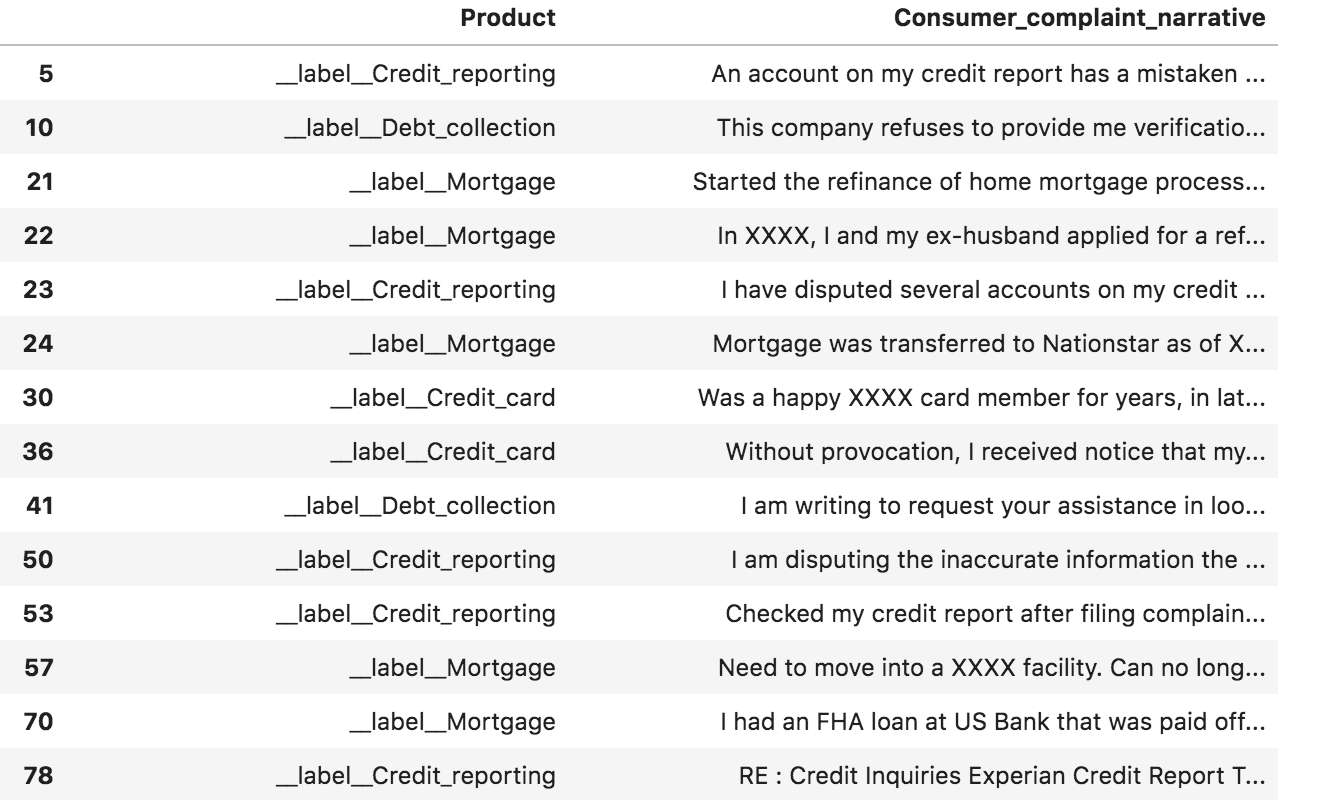
You should also check the tail using consumercomplaints.tail(200)
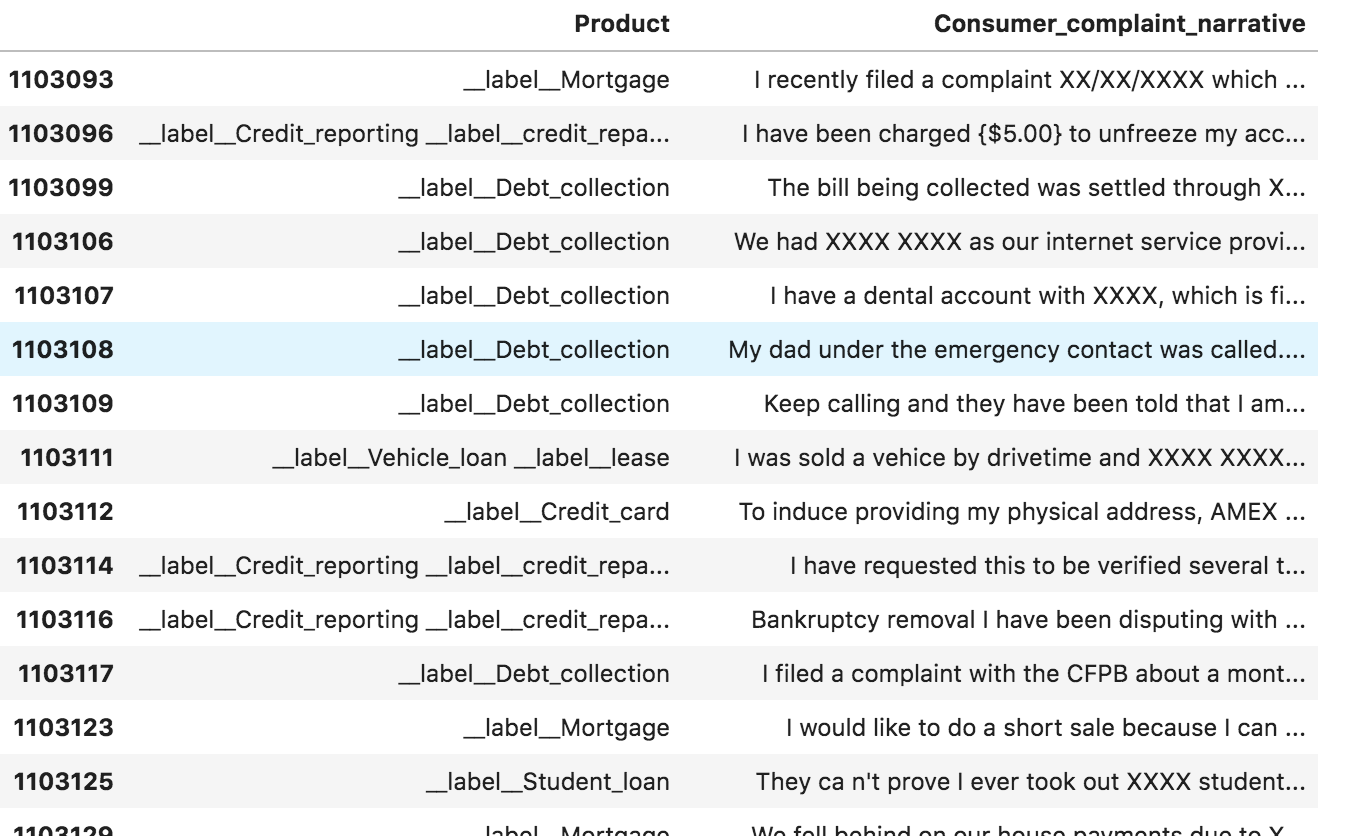
Going back to your terminal, run head consumer.complaints.txt to see if the file is loaded correctly and then count the number of records using wc consumer.complaints.txt. The output will be a large number showing the number of records. In this case, 314,263 records.
In this example, we’ll build two datasets. The first dataset will contain 80% of the records for training and the second will contain 20% of the records for validation (i.e., testing).
First, export 80% of the records using the following command:
- head -n 251410 consumer.complaints.txt > complaints.train.txt
Then export the remaining 20%:
- head -n 62853 consumer.complaints.txt > complaints.train.txt
The numbers 251410 and 62853 are based on the total number of records in the file at the time of writing. Depending on when you download the file, there may be more or less. This means that you’ll need to calculate the correct number of records yourself.
You can now train the model using fastText by running the following command:
- ./fasttext supervised -input complaints.train.txt -output model_complaints
Once you’ve received an output without any errors, you can text the model using this command:
- ./fasttext predict model_complaints.bin –
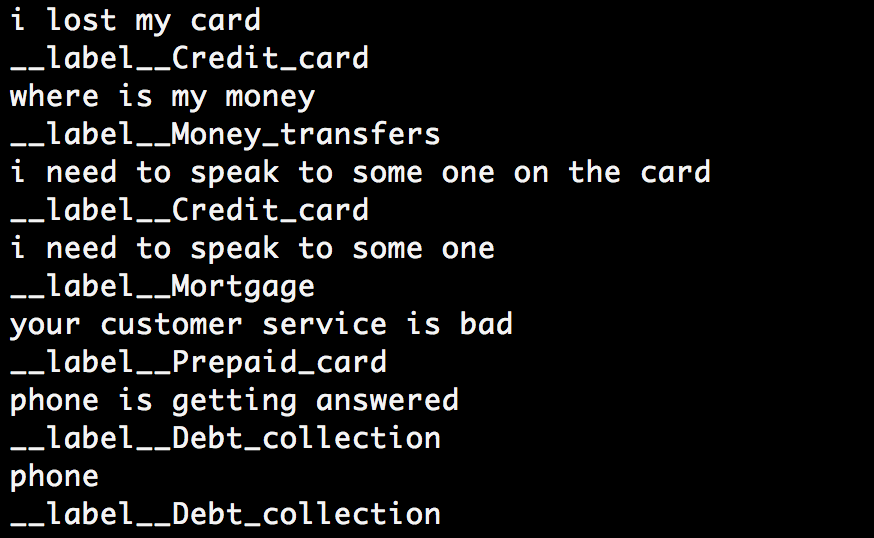
As you can see, some complaints have been classified correctly whereas others have not.
Look at the “i need to speak to some one” text, for example. This has been classified under the Mortgage label whereas it should have been classified under the Service label.
This is normal and to be expected. Text classification will rarely be perfect the first time around. It’s an iterative process that requires ongoing refinement and training with new data. That’s the whole point of machine learning applications — they get better with age.
Manage your ML with Qwak
We hope that this brief guide served as an insightful introduction to the world of text classification. It’s a process that’s growing in relevance within the ML space, and all practitioners will need to get to grips with it as part of their day-to-day.
To streamline the management of your ML, including text classification projects, we recommend the Qwak platform.
Qwak is the full-service machine learning platform that enables teams to take their models and transform them into well-engineered products. Our cloud-based platform removes the friction from ML development and deployment while enabling fast iterations, limitless scaling, and customizable infrastructure.
Want to find out more about how Qwak could help you deploy your ML models effectively? Get in touch for your free demo!
Say goodbye to complex AI & ML
Chat with us to see the platform live and discover how we can help simplify your journey deploying AI in production.
